PROYECTO
Modelo de interpolación validado para la temperatura en Aragón, España
PROYECTO DEL CURSO

Geoestadística aplicada al medio ambiente
REALIZADO POR

Luis Huascar Vildozo Guillén
Introducción
La comunidad autónoma de Aragón, España, debido a que se trata de un territorio extenso y diversificado por sus características climáticas y atmosféricas, ha sufrido diferentes episodios de olas de calor y temperaturas extremas, que hacen evidente la necesidad de estudiar el comportamiento de la temperatura y su efecto en la variabilidad climática.
En estas zonas de España, el efecto del calor en la mortalidad ha sido ampliamente estudiado, pues ambas variables presentan un comportamiento cíclico estacional. En estudios previos, se asociaron las temperaturas extremadamente elevadas con los índices de morbi-mortalidad (Roldán et al., 2011; Roldán et al., 2015).
Antecedentes
El estudio de la temperatura en Aragón cuenta con una implicancia relevante para la salud pública, pues se han estudiado la relación entre las olas de calor con la mortalidad. Esto es de alta relevancia pues los impactos del cambio climático, como la elevación de la temperatura media, puede generar una serie de impactos directos e indirectos sobre la salud pública. (Roldán et al., 2011).
En la comunidad autónoma de Aragón, se realizaron algunos estudios que permiten identificar la relación entre las variaciones de temperatura y mortalidad. Que permitieron determinar la existencia de la relación entre temperaturas extremas y mortalidad, así como determinar el umbral de temperatura máximas que genera mortalidad: 38ºC en el caso de Zaragoza, España, según Roldán et al. (2015), analizando medidas epidemiológicas y aportando elementos científicos para que las autoridades de salud puedan implementar planes de acción preventivas ante los eventos de temperaturas extremas.
Para desarrollar este tipo de estudios, se requiere de aptitudes y metodologías geoestadísticas explícitas, que nos permitan analizar, procesar y entender los datos obtenidos, junto con los modelos matemáticos detrás de los procesos de interpolación, con el fin de obtener información precisa, acertada y validada, que permita dar luces hacia la toma de decisiones y una gestión pública acorde a los riesgos climáticos.
Descripción del área de estudio
Aragón se encuentra ubicado al noreste de España. Es una zona que presenta eventos de temperatura extrema que han propiciado pérdidas tanto materiales como humanas a lo largo de las últimas décadas.
Constantemente se registran olas de calor que superan récords de gestiones previas, donde algunas estaciones de la zona registran hasta 47,4 ºC (HERALDO, 2021). Tan solo el año 2021, diversos medios de comunicación locales reportaron olas masivas de calor en la región durante los meses de julio y agosto. Estos datos superaron récords de la misma temporada del año en gestiones anteriores, lo cual enciende las alertas de las autoridades de salud.
Objetivos
Los objetivos de este estudio son los siguientes:
- Realizar un análisis exploratorio de los datos de temperatura de Aragón, España, para identificar características relevantes de los mismos.
- Escoger el modelo de interpolación más adecuado para este conjunto de datos, en base a revisión teórica y bibliográfica.
- Generar modelos de interpolación validados, para obtener un modelo con el menor error posible.
Procedimiento
Análisis exploratorio de los datos
Para ello se usan las herramientas de análisis geoestadístico:
Histograma de frecuencias
Al realizar el histograma de frecuencias, el programa genera estadísticos que representan:
- Medidas de dispersión
- Medidas de forma (kurtosis)
- Medidas de asimetría (skewness)
El histograma de frecuencias es un análisis que nos permite evidenciar el tipo de distribución de los datos, por medio de medidas de tendencia central y otros elementos.
Normal QQ plot
La gráfica de Normal QQ plot permite comparar el conjunto de datos de estudio con un modelo teórico con una distribución normal.
En caso de ser necesario, este análisis permite hacer una transformación de datos para acercar la distribución de los datos a una distribución normal.
Análisis de tendencias
El análisis de tendencias (Trend Analysis) proporciona una perspectiva tridimensional del conjunto de datos, donde los ejes X y Y representan longitud y latitud, respectivamente, mientras que el eje Z representa el valor de la variable de estudio (en este caso, la temperatura).
Este análisis nos permite visualizar más fácilmente la tendencia de distribución de los datos.
Determinación del método de interpolación más adecuado para los datos
Kriging
El Kriging es uno de los métodos de interpolación más complejos y completos. Es un método geoestadístico que permite estudiar gráficos de correlación espacial. Este método, al contener tantas opciones de variación de datos de entrada y conversión de los mismos, requiere que el técnico que realiza el modelo tome un conjunto de decisiones con el fin de mejorar el modelo de interpolación en base a la naturaleza de los datos (ESRI, 2016).
Kriging funciona a través del supuesto de que los datos que están más cerca entre ellos son más similares que los que están más alejados, pero a cierta distancia, esta relación deja de tener efecto (Fraczek, 2021).
Existe bibliografía que considera el método Kriging como el más adecuado para datos de temperatura, pues se ha usado para extrapolar estas variables tanto con fines genéricos como para estudiar, por ejemplo, el calentamiento urbano (Krause, 2021).
Obtención y validación de modelos
Es un procedimiento que permite determinar cuál es el mejor método de interpolación para un conjunto de datos. Para ello se siguen los siguientes pasos:
- Obtener muestras aleatorias de entrenamiento y de test.
- Generar un modelo de interpolación por medio de la muestra de entrenamiento.
- Usar Validation/Prediction con la muestra de test.
- Evaluar los resultados.
La siguiente figura representa en procedimiento a seguir en el presente documento, expresando ciertas características y herramientas a usar en las 3 etapas detalladas.

Resultados
Análisis exploratorio de los datos
Histograma de frecuencias
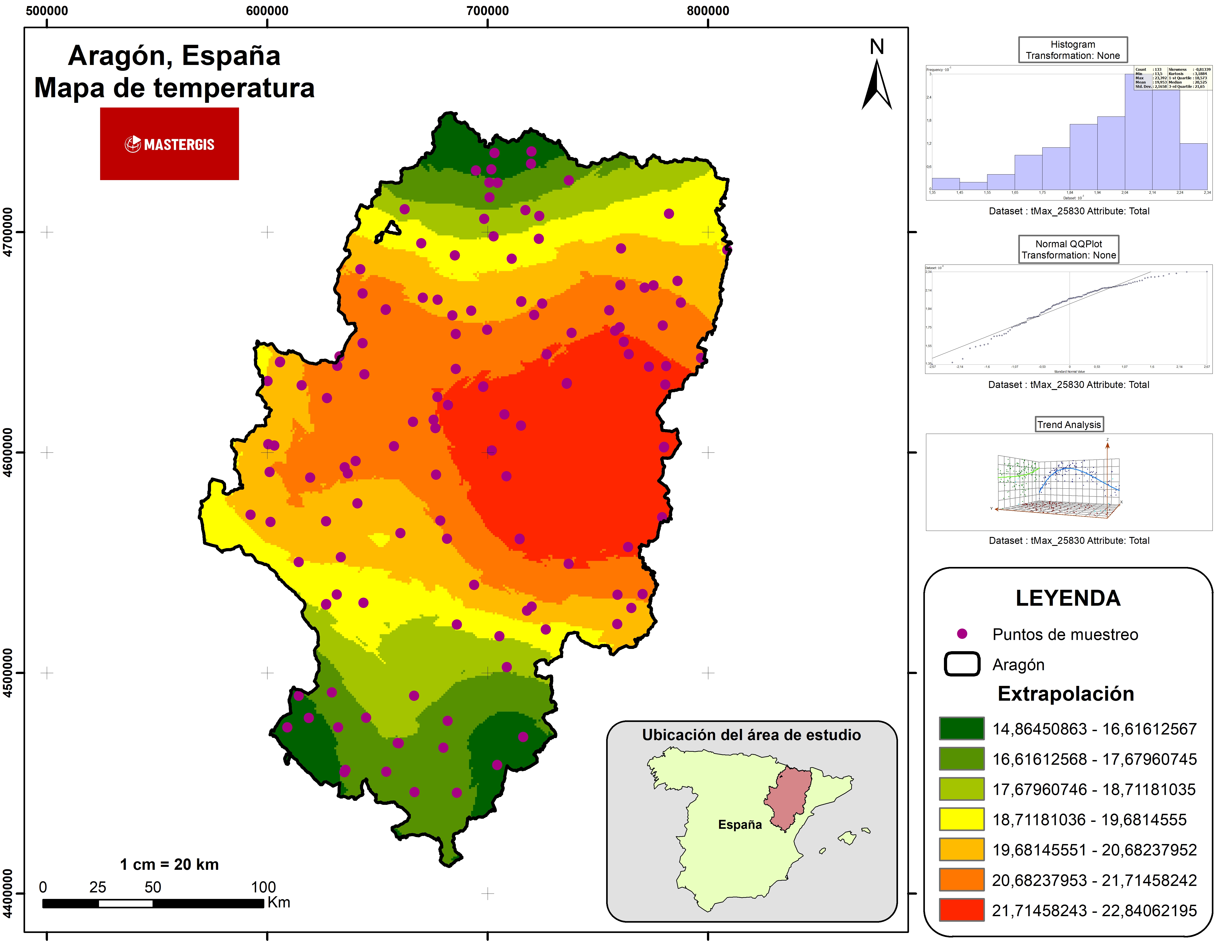
El histograma de frecuencias obtenido con los datos se presenta en la siguiente figura.

Los estadísticos obtenidos permiten evidenciar que los datos presentan una distribución leptocúrtica, debido al que la prueba de Kurtosis contiene valor positivo.
Asimismo, la prueba de Skewness evidencia que los datos tienen una asimetría negativa, por el valor negativo expresado.
Los valores relativamente cercanos entre la mediana y el promedio expresan que se trata de valores tendientes a la distribución normal (mediana=20,525; promedio=19,953).
Normal QQ plot
La gráfica de normalidad obtenida se presenta en la siguiente figura.

Al explorar los operadores para la transformación de datos se pudo observar que ninguna de las opciones de transformación (log y Box-cox) generan una mejora en la normalidad de los datos, así que se asumen que la ausencia de transformación es la mejor opción para este conjunto de datos.
Análisis de tendencias
El análisis de tendencias dio como resultado la siguiente figura.

El análisis de tendencias muestra que el orden polinomial que mejor se adapta a la distribución de los datos es el 3. Este dato será útil posteriormente al realizar el modelo de interpolación por el método Kriging.
Método de interpolación más adecuado
Inicialmente se realizó un modelo de interpolación por el método Kriging con los parámetros por defecto que el software provee. Posteriormente se realizó otro modelo variando ciertos parámetros en función del análisis exploratorio realizado en los apartados previos, usando el polinomio mejor adaptado, así como activando la dirección de búsqueda según el Análisis de tendencias. Asimismo, se activó la opción de “Optimizar modelo”.
Los 2 modelos obtenidos se compararon en términos de la predicción de errores, como muestra la siguiente figura.

Los datos presentados al lado izquierdo pertenecen a un modelo Kriging generado con los parámetros por defecto, mientras los del lado derecho pertenecen al modelo con los parámetros modificados.
Se observa una ligera mejora en los valores promedio, Raíz media cuadrática y en el promedio estandarizado con el modelo generado con variación de parámetros.
Obtención y validación de modelos de interpolación
Como resultado de estos procesos se obtuvieron todas las capas requeridas para la validación, como muestra la siguiente figura.

Así, se realizaron 4 repeticiones del proceso para obtener el modelo que mejor cumple con los parámetros planteados, obteniendo los siguientes datos:
Modelo de interpolación Nº | Error medio del modelo | Error medio validación |
1 | -0,00431347 | 0,485706 |
2 | 0,07058386 | 0,911959 |
3 | 0,0388085 | 1,060074 |
4 | 0,0521974 | 0,673252 |
Es evidente que el primer modelo de interpolación obtuvo los mejores errores (más cercanos a 0). Este primer modelo se obtuvo con los siguientes parámetros:
- Transformation type: None
- Order of trend removal: None
- Optimize model: Yes
Todos los demás parámetros se dejaron por defecto.
El resultado obtenido se presenta en el siguiente mapa.

Conclusiones
Se identificaron características del conjunto de datos de temperaturas de la región de Aragón, España, por medio de un análisis exploratorio de los datos, usando Histograma de frecuencia, Normal QQ plot y Análisis de tendencias, identificando que el conjunto de datos muestra tendencia a una distribución normal (con ligeras diferencias por evidenciar asimetrías y distribución leptocúrtica).
Asimismo, los datos mostraron mejor ajuste a un modelo teórico de distribución normal sin transformaciones. Por último, se identificó que el orden polinomial que mejor se adapta al conjunto de puntos es de tercer orden, habiendo ligeras diferencias con el segundo orden.
De igual manera, se analizaron aspectos teóricos y bibliografía previa para determinar el método de interpolación que mejor se adapte a los datos de temperatura en estudio, concluyendo que el método geoestadístico Kriging es el más adecuado para este caso, usando el tipo Ordinario de Kriging.
Asimismo, se generó un modelo de interpolación con el método Kriging validado por medio de 4 repeticiones, encontrando el modelo que menor error presente, por medio del proceso de validación de modelos, obteniendo un error medio del modelo de -0,0043 y un error medio de la validación de 0,4857. Por último, se presentaron los análisis y capas obtenidas en un mapa con las características pertinentes.
Recomendaciones
Es importante tomar en cuenta el análisis exploratorio de los datos como medidas previas a la realización de los modelos de interpolación, pues el asumir algunas características de los datos sin previamente corroborar o transformar los mismos podría dar lugar a errores o imprecisiones de los modelos, reduciendo la calidad de los resultados obtenidos.
Por otro lado, en el desarrollo del proyecto se pudo evidenciar la variación espacial de la temperatura en la zona de estudio, lo que lleva a generar preguntas sobre las causales de dicha variación. Por ese motivo sería bueno contar con capas o archivos espaciales complementarios (shapefiles o rasters) que nos permitan explorar las causales de esta variabilidad, por ejemplo, una capa de Modelo Digital del Terreno (DEM), curvas de nivel o ubicación de centros urbanos que nos permitan analizar estos detalles.
Referencias bibliográficas
ESRI. (2016). Cómo funciona Kriging. Recuperado el 11 de Mayo de 2022, de https://desktop.arcgis.com/es/arcmap/10.3/tools/3d-analyst-toolbox/how-kriging-works.htm#:~:text=La%20herramienta%20Kriging%20ajusta%20una,de%20salida%20para%20cada%20ubicaci%C3%B3n.
Fraczek, W. (20 de Septiembre de 2021). Mejorar las interpolaciones para cartografiar temperaturas. Obtenido de https://learn.arcgis.com/es/projects/improve-interpolations-to-map-temperature/
HERALDO. (18 de 8 de 2021). La ola de calor dejó récords de temperaturas en 40 puntos de Aragón. Obtenido de https://www.heraldo.es/noticias/aragon/2021/08/18/la-ola-de-calor-dejo-records-de-temperaturas-en-40-puntos-de-aragon-1513574.html
Krause, E. (22 de Noviembre de 2021). Analizar el calentamiento urbano mediante kriging. Obtenido de https://learn.arcgis.com/es/projects/analyze-urban-heat-using-kriging/
Roldán, E., Gómez, M., Pino, M., & Díaz, J. (2015). The impact of extremely high temperatures on mortality and mortality cost. International Journal of Environmental Health Research, 25(3), 227-287.
Roldán, E., Gómez, M., Pino, M., Pradas, M., & Díaz, J. (2011). Determinación de zonas isotérmicas y selección de estaciones meteorológicas representativas en Aragón como base para la estimación del impacto del cambio climático sobre la posible relación entre mortalidad y temperatura. Revista Española de Salud Pública, 85(6), 603-610.
REALIZADO POR
Luis Huascar Vildozo Guillén
PROYECTO DEL CURSO
Geoestadística aplicada al medio ambiente
Alejandra Duque