PROYECTO
Modelo de interpolación del promedio histórico (1997-2021) de temperaturas medias de la Comunidad Autónoma de Aragón, España .
PROYECTO DEL CURSO

Geoestadística aplicada al medio ambiente
REALIZADO POR

Florencia Chomnalez
Título del Proyecto
Modelo de interpolación del promedio histórico (1997-2021) de temperaturas medias de la Comunidad Autónoma de Aragón, España
Introducción
Este trabajo pretende poner en práctica todos los conceptos teórico prácticos vistos en el curso de Geoestadística con ArcGIS dictado por MasterGIS.
Partiendo del análisis de datos climatológicos de un área de estudio sugerida por los docentes se realizará un análisis exploratorio de los datos para obtener un modelo de temperaturas medias del área de estudio, aplicando la validación de los modelos en forma comparada para seleccionar aquél que tenga el menor error posible, siendo entonces más cercano a la realidad.
Antecedentes
Este estudio surge de encontrar distinta bibliografía y fuentes informativas (Roldán et al, 2015) que evidencian una relación entre las altas temperaturas de la región de Aragón con su impacto en la salud humana. (Heraldo, 2022) siendo estas olas de calor las causantes de un pico en las asistencias de urgencia y en el aumento de la mortalidad asociada a la extrema variabilidad climática.
La geoestadística nos ayudará a generar modelos de interpolación para poder analizar la variabilidad espacial de la temperatura en el área de estudio. Para ello haremos distintos modelos que serán validados en función de las metodologías de trabajo aprendidas en el curso para seleccionar aquel modelo más optimo.
Análisis de este tipo suelen ser de utilidad para la toma de decisiones en el ámbito público tanto para la gestión ambiental como para la gestión de la salud. Para posibilitar la gestión de una problemática ambiental dada es conocer la realidad, en este caso en base a información estadística histórica modelizada.
Descripción del área de estudio
Se define como área de estudio la comunidad autónoma de Aragón que se localiza al norte de España. Limita al norte con Francia (Occitania y Nueva Aquitania), por el oeste con Castilla-La Mancha, Castilla y León, La Rioja, Navarra y por el este con Cataluña y la Comunidad Valenciana. La comunidad cuenta con dos cadenas montañosas. El Pirineo concentra en la provincia de Huesca las mayores altitudes, con el pico Aneto como techo de Aragón y de la cordillera. El Aneto cuenta con una altitud de 3.404 metros sobre el nivel del mar. El sistema Ibérico limita con la meseta central y su pico más alto es el Moncayo, que, con 2.313 metros sobre el nivel del mar, se alza entre las provincias de Zaragoza y Soria. La región presenta el Parque Nacional de Ordesa y Monte Perdido. Creado en 1918, se trata del segundo parque nacional más antiguo de España.
En Aragón el clima puede considerarse, en general, como de tipo mediterráneo continental, aunque su irregular orografía hace que se creen varios climas o microclimas a lo largo y ancho de toda la comunidad. Desde el de alta montaña de los Pirineos centrales al norte, con hielos perpetuos (glaciares), hasta el de zonas esteparias o semidesérticas, como los Monegros, pasando por el clima continental intenso de la zona de Teruel-Daroca (Prats Cuadrat, 2004).
Las temperaturas medias anuales en Aragón son relativamente altas debido a la protección que recibe el territorio de los sistemas montañosos; en el valle del Ebro la temperatura media anual es de alrededor de 15 °C y en las zonas más altas tan solo de 7 °C. La alta amplitud térmica es muy notable en casi todo el territorio, sobre todo en la zona de Teruel donde en invierno se suele estar por debajo de los -10 °C, mientras que en verano alcanzan los 35 °C. El resto del territorio ronda entre los 10 °C y los 14 °C de media anual.
En el año 2022 en la región hubo dos oleadas de altas temperaturas hacia fines del mes de julio. Estas han impactado en la salud de la población. Muchos individuos han tenido que ser asistidos de urgencia y otros han muerto a causa de las elevadas temperaturas. De acuerdo a las noticias de Heraldo (2022) estos hechos se desprenden de la primera evaluación del Plan de Vigilancia de los Efectos del Exceso de Temperaturas sobre la Salud en Aragón, elaborado por la Dirección General de Salud Pública del Departamento de Sanidad, tras analizar el período comprendido entre el 1 de junio y el 31 de julio.
En base a estos antecedentes climáticos y sus consecuencias de salud en la población local, ya sea por la necesidad de atención de urgencia por este suceso en particular de aumento de la mortalidad ligado a las altas temperaturas, es que se propone en ese trabajo estudiar el comportamiento histórico de las temperaturas medias en esta región en base a una serie de datos históricos promedio entre el año 1997 y el año 2021 (Gobierno de Aragón, 2023).
Objetivos del proyecto
Objetivo General
- Aportar herramientas para analizar la variabilidad de la temperatura en la comunidad autónoma de Aragón a través del análisis basado en geoestadística.
Objetivos Específicos
- Recopilar la información espacial necesaria para poder analizar el conjunto de datos disponible,
- Realizar un análisis exploratorio de los datos de temperatura de Aragón, España, disponibles entre 1997 y 2021,
- Generar distintos modelos de interpolación de temperatura promedio en el área de estudio en base a los conceptos teórico-prácticos aprendidos en el curso,
- Validar los modelos, considerando el análisis exploratorio de datos realizado previamente, comparar los resultados de todos los modelos,
- seleccionar como modelo final, aquél que haya sido optimizado de manera tal que tenga el menor error posible,
- Realizar un mapa final que muestre la variabilidad climática en toda el área de estudio por medio de cartografiar el modelo final mediante un SIG.
Metodología
Se presenta a través de un flujograma de trabajo los distintos pasos que se requieren implementar para arribar a los objetivos propuestos:

Figura 1: Flujograma de trabajo
Procedimiento
- Análisis Exploratorio de los datos
El análisis exploratorio de los datos espaciales es indispensable para describir el comportamiento del conjunto de datos que queremos trabajar. A partir de distintos elementos de análisis podemos entender la variabilidad de la muestra, si se acerca o aleja a una distribución normal para luego poder ajustar estos datos para poder acercarlos más a la realidad, obteniendo luego modelos de interpolación ajustados a la realidad o más bien lo más ajustados posible.
- Análisis del Histograma de frecuencias
Cuando analizamos el histograma de frecuencia de los datos podemos ver distinto tipo de medidas: de dispersión, de forma y de asimetría.
Por ejemplo, podemos ver si los datos tienen un comportamiento normal, si la media coincide con la mediana, observar los valores mínimos y máximos, etc.
En este caso tomamos los datos del shape de puntos ‘tmax_25830’ que contiene los puntos de temperaturas medias del área de estudio y lo clasificamos por el atributo ‘total’. Visualizamos como resultado el histograma de frecuencias para este conjunto de datos.

Figura 2: Histograma de Frecuencias sin transformaciones
Analizando los distintos datos vemos que los valores mínimos se acercan a 13,5 ºC y los máximos a 23,392 ºC. La media no coincide con la mediana. Este es de 19,953 y la mediana es de 20,525. La desviación estándar es de 2,1658.
A partir de este análisis podemos inferir que este conjunto de datos tal como se muestra no presentan una distribución normal. Esto se debe a que analizando las medidas de forma como la curtosis vemos que está lejano a cero, es de 3,1884 y la asimetría es negativa, siendo de -0,81339. Esta distribución de los datos es leptocúrtica.
Sería deseable ajustar los datos lo más posible para que presenten una distribución normal o lo más ajustada posible para arribar a resultados confiables.
Para ello, intentamos realizar una transformación logarítmica y Box-Cox, pero los resultados no fueron más ajustados probando con ambas opciones por lo cual optamos por no aplicar ningún ajuste de histograma.

Figura 3: Histograma de Frecuencias aplicando una transformación logarítmica

Figura 4: Histograma de Frecuencias aplicando una transformación Box-Cox
- Normal QQPlot
En estadística, un gráfico QQ ("Q" viene de cuantil) es un método gráfico para el diagnóstico de diferencias entre la distribución de probabilidad de una población de la que se ha extraído una muestra aleatoria y una distribución usada para la comparación.
Un ejemplo del tipo de diferencias que pueden comprobarse es la no normalidad de la distribución de una variable en una población. Si la distribución de la variable es la misma que la distribución de comparación se obtendrá, aproximadamente, una línea recta, especialmente cerca de su centro. En el caso de que se den desviaciones sustanciales de la linealidad, los estadísticos rechazan la hipótesis nula de similitud (Gnanadesikan, 1977)
Analizando nuestro QQPlot vemos que los datos no siguen una distribución normal, pues en la comparación se alejan mucho del centro de la línea de tendencia.
Se observa un desajuste entre los datos y la curva de distribución normal. Aparentemente, los datos por debajo de 1755 °C son los que más se alejan de la distribución normal, seguidos por los datos ubicados por encima de 22,15 °C.
Los datos que se observan más alejados de la distribución normal se encuentran en principio en el norte, sur y parte en el centro del área de estudio. Sería recomendable agregar más puntos de medición en esas zonas en donde encontramos estas distancias respecto al análisis de la distribución del conjunto de datos.

Figura 5: Normal QQPlot
- Mapa de Voronoi
El mapa o diagrama de Voronoi de un conjunto de puntos en el plano es la división de dicho plano en regiones, de tal forma, que a cada punto se le asigna una región del plano formada por los puntos que son más cercanos a él que a ninguno de los otros objetos.
En sentido geométrico, basado en una función distancia, el diagrama de Voronoi establece los límites de las áreas de influencia del punto utilizado como centro de cada área, de forma que para un punto cualquiera se puede saber a qué área pertenece y qué centro es el más cercano, según la función distancia escogida, que típicamente es la euclídea, la cual genera regiones convexas.
En nuestro mapa de temperaturas, sirve para analizar si la distribución de estas está bien repartida por un área y así determinar su variabilidad. Por ejemplo, queremos saber cómo están distribuidas las zonas con mayores temperaturas. A partir de las posiciones geolocalizadas de cada punto de las muestras podemos generar un diagrama de Voronoi tratándolas como los centros de cada región, y podemos superponer el diagrama resultante a un mapa para ver su distribución espacial. Esto nos permite visualmente ver las tendencias en la distribución de los datos.
Del análisis del mapa de Voronoi se desprende una aparente tendencia de los datos en sentido Este-Oeste, habiendo mayores temperaturas al Este que van disminuyendo hacia el Oeste. Por otra parte, esta tendencia sucede de Norte a Sur, aunque comienza a haber en el Norte bajas temperaturas relativas, que van aumentando hacia el Centro y que vuelven a disminuir hacia el Sur.

Figura 6: Mapa de Voronoi tipo ‘media’ en donde se visualiza una tendencia de las temperaturas Este-Oeste y Norte-Sur.
- Análisis de Tendencia
Para continuar con el análisis de tendencia analizamos distintos gráficos considerando el análisis de la distribución espacial del conjunto de datos en el eje X (Este-Oeste) y en el eje Y (Norte-Sur) observando el sentido o dirección de la tendencia en cada eje.
Ajustamos el conjunto de datos al orden de polinomio 2 y vemos que el más acertado para nuestra muestra.

Figura 7: Gráfico de Tendencia de la temperatura en el eje X (Este-Oeste)

Figura 8: Gráfico de Tendencia de la temperatura en el eje Y (Norte-Sur)
e) Semivariograma
El variograma o semivariograma es una herramienta que permite analizar el comportamiento espacial de una variable sobre un área definida, obteniendo como resultado un variograma experimental que refleja la distancia máxima y la forma en que un punto tiene influencia sobre otro punto a diferentes distancias.
Sabemos que, en un semivariograma, las cosas más cercanas son más predecibles y tienen menos variabilidad. Mientras que las cosas distantes son menos predecibles y están menos relacionadas.
Entonces, estos gráficos resultan de gran utilidad para determinar el grado de autocorrelación espacial existente en el conjunto de datos.
Nuestro ejemplo contiene 133 muestras de temperatura media en un área de 4.773.080 ha. En se observa una tendencia de mayores temperaturas en sentido noroeste, siendo las mismas más bajas en los extremos Norte y Sur del área de estudio.
En esta instancia cabe preguntarnos:
- ¿Cuán predecibles son los valores de un lugar a otro?
- ¿Son los valores conocidos más cercanos entre sí más similares que los valores más alejados?
Como hemos visto en el curso, esta idea se puede describir con dependencia estadística o autocorrelación. Además, la autocorrelación (que asume que las cosas más cercanas entre sí son más similares que las más distantes) proporciona información valiosa para la predicción que es lo que queremos hacer al momento de llevar a la práctica una interpolación.
Para entender la dependencia espacial, la podemos estimar como vimos con un semivariograma. Estos gráficos de dos ejes toman 2 posiciones de muestra y llaman a la distancia entre ambos puntos h.
En el eje X, se traza la distancia (h) agrupada. Tomando cada conjunto de 2 ubicaciones de muestra. Se mide la varianza entre la variable de respuesta (temperatura) y se la traza en el eje Y.


Figura 9: Semivariorama general
Si queremos entrar en detalle sobre la relación de distancias específicas podemos tomar ejemplos de puntos individuales.

Figura 10: Selección de un punto alejado en el Semivariorama (extremo derecho)
Podemos ver que el punto seleccionado representa 2 puntos en el mapa. Esto tiene sentido porque están muy alejados unos de otros. Por lo tanto, su posición extrema derecha en el semivariograma. En realidad, es este punto resaltado a continuación:

Figura 11: Representación de la distancia y su relación entre 2 puntos de la selección del punto del semivariograma de la figura 10.
Es importante destacar que también tienen una gran diferencia del valor medio en esa distancia de retraso en particular. Se posiciona más alto en el eje Y si la semivarianza es alta. Por ende, la semivarianza es más pequeña a distancias más cercanas y aumenta con distancias más grandes.
Estamos observando la distancia entre 2 muestras y su variabilidad. Un semivariograma considera todos los puntos y su distancia con varianza. Por eso los semivariogramas tienen tantos puntos. Si seleccionamos todos los puntos en el semivariograma veríamos todas las relaciones de distancia entre sí para ver todos los diferentes conjuntos de puntos que se están trazando en el semivariograma.
Ahora bien, elegiremos un conjunto de puntos en el centro del semivariograma y pegados al eje X. En este ejemplo, vemos que ese conjunto de datos muestra más relaciones de distancia al tratarse de un conjunto de datos mayor en lugar de tomar un punto aislado de un extremo del semivariograma.

Figura 12: Representación de la distancia y las relaciones entre varios puntos del semivariograma
En resumidas cuentas, vemos que, en los puntos de la muestra con distancias cortas, la diferencia de valores entre puntos tiende a ser pequeña. En otras palabras, la semivarianza es pequeña.
Pero cuando las distancias de los puntos de la muestra son más lejanas, es menos probable que sean similares. Esto significa que la semivarianza es mayor.
A medida que aumenta la distancia de los puntos de muestreo, ya no existe una relación entre éstos. Su varianza comienza a estabilizarse y los valores de la muestra no están relacionados entre sí.
Entonces, los semivariogramas proporcionan un paso preliminar muy útil para comprender la naturaleza de los datos.
Cada fenómeno tiene su propio semivariograma y su propia función matemática. Habiendo analizado la relación entre valores y distancias, podemos determinar el mejor modelo de interpolación más ajustado al tema propuesto, en este caso probaremos usar el IDW para realizar nuestras predicciones.
Nos detuvimos en detalle en analizar los semivariogramas porque consideramos que es una de las herramientas más potentes aprendidas. Esto se debe a que el modelo de semivariograma influye en la predicción de esos valores desconocidos durante la interpolación si usáramos la de Kriging, es decir, tendrá en cuenta el semivariograma de nuestro conjunto de datos, cosas que podemos ajustar luego en la interpolación habiendo hecho un análisis exploratorio exhaustivo de los datos. Si no funcionara el modelo IDW procederemos a hacer interpolación Kriging considerando estos análisis previos.
- Muestreo Aleatorio
El muestreo aleatorio nos servirá para dividir el conjunto de datos (133 entidades). Una parte de esos datos servirán para realizar nuestro modelo de interpolación y la otra parte para validar dicho modelo.
Para ello vamos a la herramienta ‘Subset features’ del Geoestatistical Analyst. Esta herramienta divide el conjunto de datos original en dos partes: una parte que se utilizará para modelar la estructura espacial y producir una superficie (muestras de entrenamiento), y la otra que se utilizará para comparar y validar la superficie de salida (muestras de testeo). Como tenemos 133 datos podemos usar una muestra de entrenamiento del 80% (106), dejando un 20% (27) para las muestras de testeo.

Figura 13: Muestreo aleatorio: definición de muestras de entrenamiento y de testeo para generar y validar el modelo de interpolación.
- Interpolación, validación y comparación de los modelos
En primera instancia haremos a partir del conjunto de datos de entrenamiento una interpolación IDW y analizaremos los resultados.

Figura 14: Interpolación IDW en base a muestras de entrenamiento: Paso 1.
Luego de determinar con qué modelo trabajar, recordamos el análisis que hicimos en la etapa exploratoria de datos y seleccionamos un Power de 2 (figura 15).

Figura 15: Interpolación IDW en base a muestras de entrenamiento: Paso 2
Fuimos variando los sectores y los ejes hasta obtener una predicción más ajustada, intentando que el error medio sea lo más cercano a cero posible (figuras 17 y 18)

Figura 16: Interpolación IDW en base a muestras de entrenamiento: sin ajuste

Figura 17: Interpolación IDW en base a muestras de entrenamiento: con ajustes varios.

Figura 18: Interpolación IDW en base a muestras de entrenamiento: con ajustes finales.
Luego de varios ajustes hemos podido disminuir el error medio de 0,1810566 a 0,1391408. Obtenemos un nuevo modelo, aunque apenas más ajustado.
En la validación del primer modelo generado vemos que la media del error es de: -0,348484.

Figura 19: Validación Modelo 1: media del error
En la validación del segundo modelo generado con ajustes la media del error es de -0,228663, siendo un poco más ajustado el error. Si siguiéramos trabajando, ajustando los datos podríamos mejorar mucho más el modelo.

Figura 20: Validación Modelo 2: media del error
Ahora calculamos el error al cuadrado para ambos modelos. En el modelo 1, la media de este es de 0,788472.

Figura 21: Validación Modelo 1: cálculo del error cuadrático medio
Cuando vamos al segundo Modelo, vemos que la media del error al cuadrado es de 0,707674.

Figura 22: Validación Modelo 2: cálculo del error cuadrático medio
Por último, calculamos la raíz del error al cuadrado y en el primer caso nos da 0,88795, y en el segundo caso nos da 0,841233.
- Selección del modelo óptimo
En función de los análisis realizados seleccionamos el modelo óptimo como resultado de interpolar el conjunto de datos en base a una muestra de entrenamiento.
Nos quedamos con el modelo ajustado (modelo 2) tras haber comparado ambos modelos (figura 21)

Figura 23: comparación de las predicciones de error de los modelos obtenidos
- Elaboración del Mapa final
Resultados
Es importante destacar que se podría haber seguido trabajando en ajustar ya sea la muestra de los datos (realizar más muestras de entrenamiento) ya que estos se generan al azar y cambian cada vez que generamos las muestras tanto las de entrenamiento como las de testeo. Podríamos ajustar los porcentajes, realizar varias pruebas y obviamente los modelos arrojarían errores diferentes, puede que más ajustados o que no. Si quisiéramos ajustar aún más el modelo entonces podemos o bien trabajar más en el muestreo aleatorio o bien trabajar más en ajustar los parámetros de la interpolación para acercarnos a un error de la media más cercano a cero. También estos resultados nos muestras que, si bien es un modelo que para el objetivo de este curso nos es útil, podría ser que si eligiéramos el método Kriging estos modelos sean óptimos. Esto es porque podemos tener en cuenta lo que vimos en la etapa de explotación de datos especialmente con los semivariogramas.

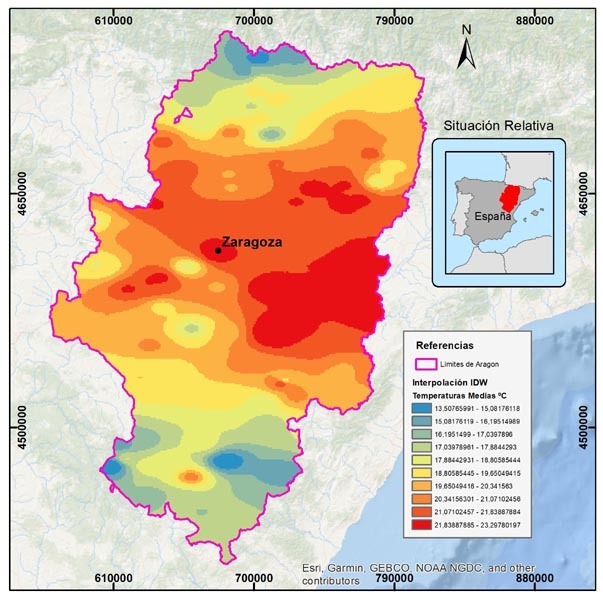
Figura 24: Mapa final de distribución de las temperaturas máximas medias en Aragón.
El presente mapa se puede ver en mejor resolución en el pdf adjunto en el trabajo, así como en las capas de información adjuntas.
Conclusiones
En este mapa visualizamos la distribución de las temperaturas máximas medias históricas entre 1997-2021. Podemos ver a través del modelo de predicción resultante de la interpolación de tipo IDW, que las máximas temperaturas se concentran en el centro del área de estudio, yendo hacia el norte y sur de la Comunidad de Aragón decrecientes. La localidad de Zaragoza, ciudad más poblada de la región, presenta los valores máximos de temperatura.
Recomendaciones
Para realizar estudios de este tipo, es imprescindible realizar el muestreo aleatorio de los datos, para poder validar a través de muestras de testeo el modelo resultante, elegir el óptimo. Es indispensable el análisis exploratorio de los datos puesto que nos ayuda a ajustar mejor nuestros modelos y poder seleccionar el que más se ajuste a nuestros objetivos de trabajo.
Si bien para este trabajo elegimos hacer el método de interpolación IDW, no descartamos que el modelo Kriging mejore aún más los resultados.
Referencias bibliográficas
- Gobierno de Aragón (2023). Estadísticas de clima. Datos climatológicos. Disponible en: https://www.aragon.es/-/clima-/-datos-climatologicos
- Gnanadesikan, R. (1977) Methods for Statistical Analysis of Multivariate Observations, Wiley ISBN 0-471-30845-5.
- Heraldo (2022). Las olas de calor dejan en Aragón un incremento de las asistencias urgentes y un aumento de la mortalidad. (09/08/2022). Disponible en: https://www.heraldo.es/noticias/aragon/2022/08/09/olas-calor-dejan-aragon-incremento-asistencias-urgentes-y-aumento-mortalidad-1592640.html
- Prats Cuadrat (2004). EL clima de Aragón. Departamento de Geografía y Ordenación del Territorio. Universidad de Zaragoza. ISBN 84-96214-29-X.
Disponible en: https://web.archive.org/web/20130928004745/http://age.ieg.csic.es/fisica/docs/003.pdf
- Roldán, E., Gómez, M., Pino, M., & Díaz, J. (2015). The impact of extremely high temperatures on mortality and mortality cost. International Journal of Environmental Health Research, 25(3), 227-287. Disponible en: https://pubmed.ncbi.nlm.nih.gov/25104053/
Archivos adjuntos
Se adjunta la principal información espacial generada (en un archivo zip) que fue utilizada para arribar al resultado final, el proyecto y el Mapa final en formato pdf.
REALIZADO POR
Florencia Chomnalez
PROYECTO DEL CURSO
Geoestadística aplicada al medio ambiente
Alejandra Duque